
By Bruce Davie and Amar Padmanabhan
There’s been a lot of discussion lately about adopting a “cloud native” approach to mobile and wireless networking, especially with the transition to 5G. The general idea is that cloud native principles, when applied to networks, can lower costs, simplify operations, and make for a robust system that recovers quickly in the event of a failure.
That may explain why we’re seeing a flurry of “cloudification” of networking equipment and design—think containers, microservices, and control and user plane separation (CUPS). But it takes more than a few buzzwords to make an architecture cloud native. Here are five defining traits that have guided our development of Magma to bring the benefits of the cloud to the world of networking.
1. Runs on commodity hardware
Most traditional networking equipment is proprietary, bundling the software with precisely specified and configured hardware. But cloud native architectures leverage low-cost commodity hardware. Performance is achieved through the use of scale-out approaches, and reliability is achieved through software techniques that deal with failures of unreliable hardware. Scale-out and planning for failure are themselves key tenets of cloud native architecture, as discussed below.
From its inception, Magma has been designed to be easy to operate in diverse environments on commodity hardware. Any component can be replaced at minimal cost and disruption to the network.
2. Scales out rather than up
A cloud native approach achieves scale by horizontally adding more commodity devices, rather than scaling up the capacity of individual, monolithic systems. Magma is based on a distributed architecture that scales out. Capacity is increased by adding small devices throughout the network—for example, networks can deploy hundreds of access gateways around radio towers instead of adding a few large boxes to the core as is common in traditional EPC designs. This distributed architecture is also important when it comes to our next point, designing for failure.
3. Creates small fault domains
In any cloud system, it is expected that individual components will fail, and failure is treated as a common part of the operational flow of the system. Many of Magma’s design decisions flow from that premise. In traditional telco architectures, by contrast, failures are assumed to be rare and are handled through specific exception paths, like hot standbys and fully redundant services.
A failure should impact as few users as possible (i.e., fault domains must be small) and should not affect other components. For example, a failure in a small access gateway might affect only a few hundred customers. Conversely, if a network built upon two large cores has a failure in one of its cores, half of its customers may lose service.
It’s not sufficient to just divide a large monolith into smaller components. You also need to localize the state within components to limit the impact of failures. Magma does this by localizing the state associated with any given user equipment (UE) to a single access gateway. Thus, the impact of component failure is limited: only the UEs served by a given access gateway are impacted. The access gateway is the location for per-UE “runtime state,” which depends on events such as the powering on of UEs or the movement of a UE to the coverage area of a new base station. By contrast, UE runtime state tends to be spread among components in traditional 3GPP implementations.
While the runtime state is localized to the relevant access gateway, the configuration state is stored centrally in the Magma orchestrator, because configuration is a network-wide property that is provided through the central API. If a component of the orchestrator fails, it only prevents updates to configuration, but does not impact the runtime state; hence, UEs can continue to operate even if the orchestrator is restarting.
4. Simplifies operations
The scalability of cloud native systems applies as much to operations as to performance. Centralized control planes, such as those found in software-defined networks (SDN), have emerged as a way to simplify the operations of networks. Whereas centralized control was once viewed as an unacceptable single point of failure or a scaling bottleneck, it is now well understood that reliable, logically centralized controllers can be built from a collection of commodity servers. It’s much simpler to operate a whole network when it is viewed from a central point of control, rather than determining how to configure each network device individually.
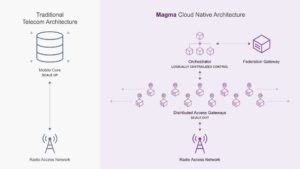
Magma takes a cloud native approach with distributed access gateways and logically centralized control.
The logically centralized point of control in Magma is the orchestrator, and it loosely corresponds to a controller in an SDN system. It is implemented on a set of machines, any of which may fail without bringing down the orchestrator. This set of machines exposes a single API from which the network as a whole may be configured and monitored. As the size of the network increases and more access gateways are added, the operator maintains a single, centralized view of the network.
Access gateways represent a distributed data plane implementation and also contain local control-plane components. The federation gateway implements a set of standard protocol interfaces to allow a Magma-enabled system to interoperate with standard cellular networks.
Separated control plane and data plane
Like SDN systems, Magma separates the control plane and data plane. This is essential to the simplified operational model, but also affects reliability. Failure of a control-plane element does not cause the data plane to fail, although it may prevent a new data-plane state from being created (e.g., bringing new UE online). This is a more complete separation than provided by the CUPS specification of 3GPP as we’ve discussed previously.
Magma’s data plane, running in the access gateways, is software-controlled and programmed through well-defined and stable interfaces (similar in principle to OpenFlow) that are independent of hardware. Again, this is the same approach as taken in SDN and enables the data plane to leverage commodity hardware and easily evolve over time.
5. Uses a desired state model
Similar to many cloud native systems (like Kubernetes), Magma uses a desired state configuration model. APIs allow users or other software systems to configure the intended state, while the control plane is responsible for ensuring that this state is realized. The control plane takes on the responsibility of mapping from the operator’s intended state to the actual implementation in the access gateways, reducing the operational complexity of managing a large network.
The desired state model has been proven effective in other cloud native contexts because it enables components to simply compare the current state with the desired state, and then make adjustments as needed. For example, if the desired state is that there are two sessions active, the control plane monitors the system to ensure it meets the requirement and takes action to activate a session if it is missing. By contrast, traditional 3GPP implementations have used a “CRUD” (create, read, update, delete) model, in which a sequence of actions (create new session or update session, for example) determine the state. In the event of a message loss or component failure, it becomes hard to determine if the current state of a component is correct.
Unlocking the advantages of cloud native architecture
While many of these design decisions might seem obvious, they are fairly different from the principles of the standard 3GPP architecture. For example, even though 3GPP has the concept of CUPS, control plane elements often hold some user plane (data plane) state. The proper separation of control and data planes leads to a more robust architecture with better upgradability.
Ultimately, it doesn’t matter what we call the architecture. What matters is how well it scales, how it handles failures, and how easy it is to operate. By adopting technologies and principles from cloud services, Magma delivers a mobile network solution that is robust, leverages commodity hardware, scales from small to large deployments gracefully, and offers a central point of control for operational simplicity.